CoderAI Gallery
Screenshots from the CoderAI web interface, focused on the model configuration workflow: quantization, Flash Attention 2, RAM fallback policy, and per-component tuning for image/video pipelines.
Jump to: Screenshot 1 Screenshot 2 Screenshot 3 Screenshot 4 Screenshot 5 Screenshot 6 Screenshot 7 Screenshot 8 Screenshot 9 Screenshot 10
Model configuration in practice.
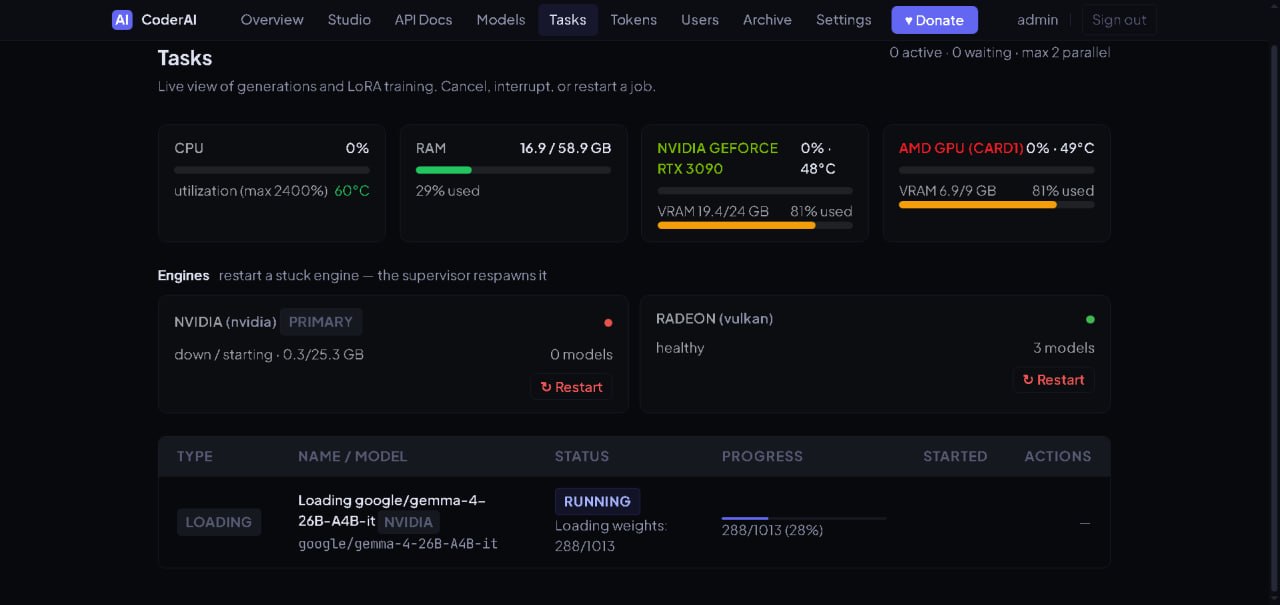
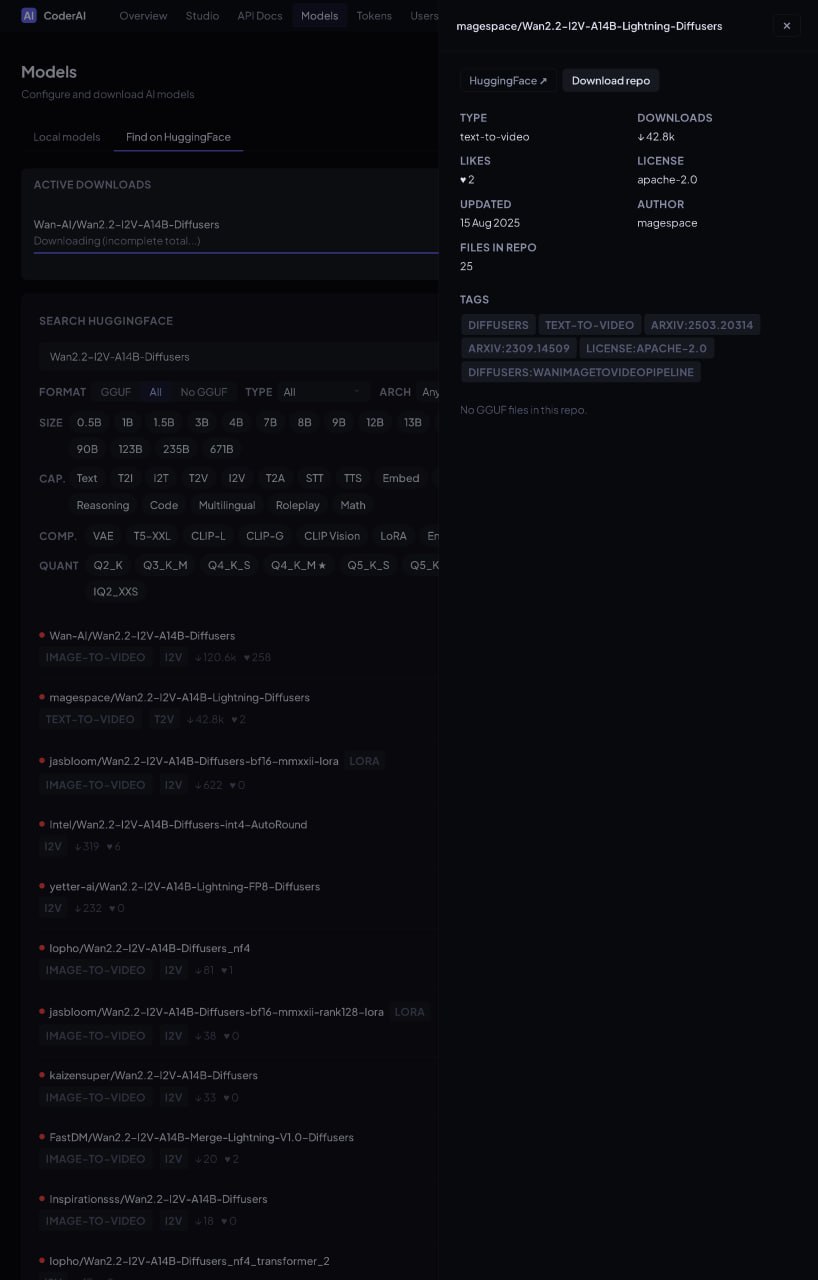
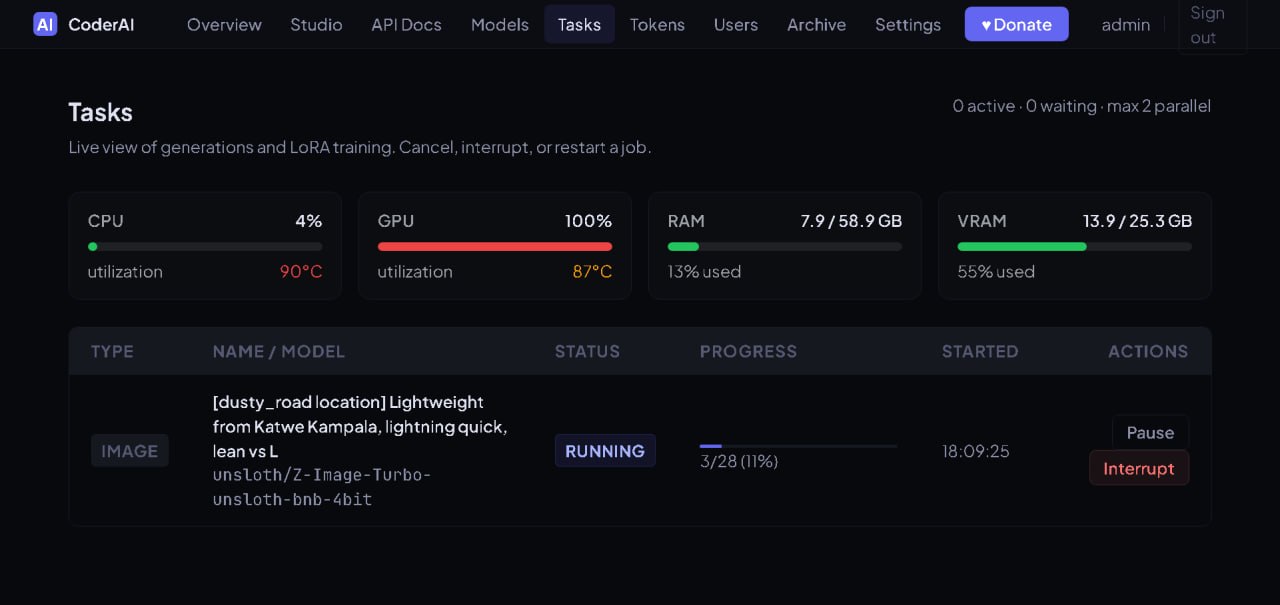
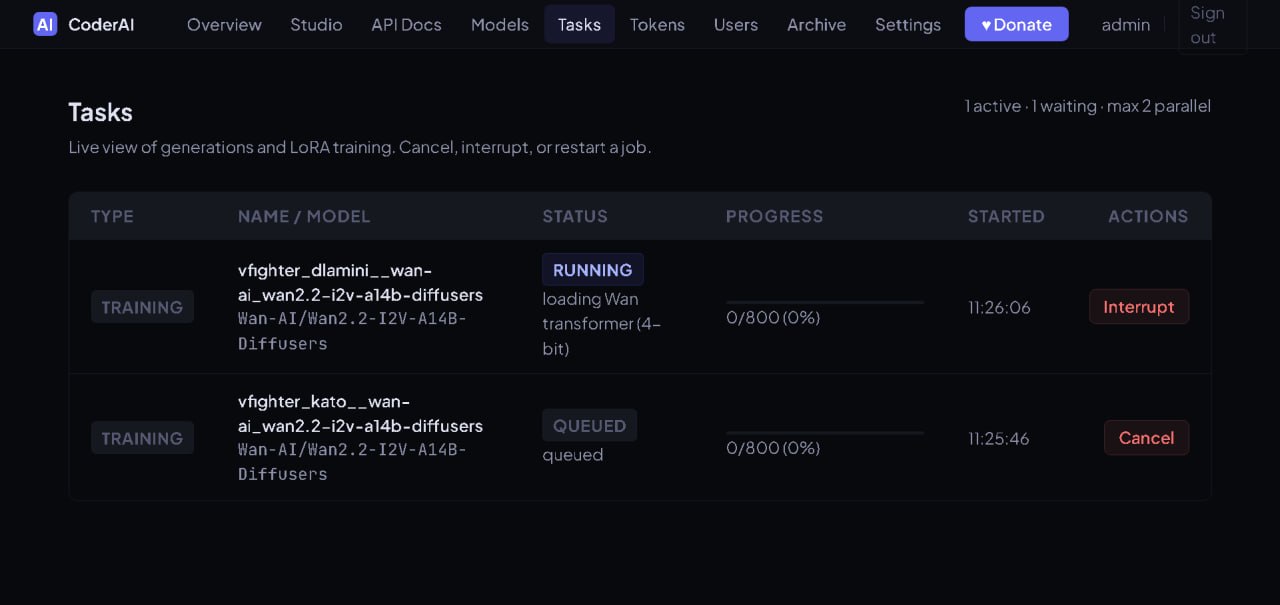
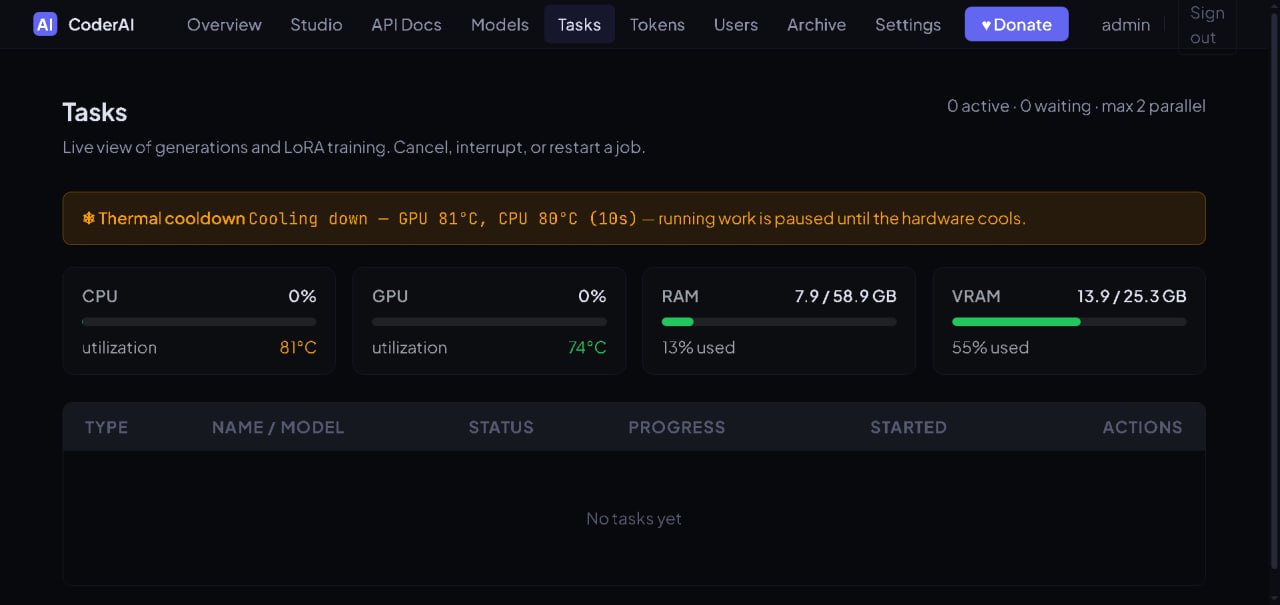
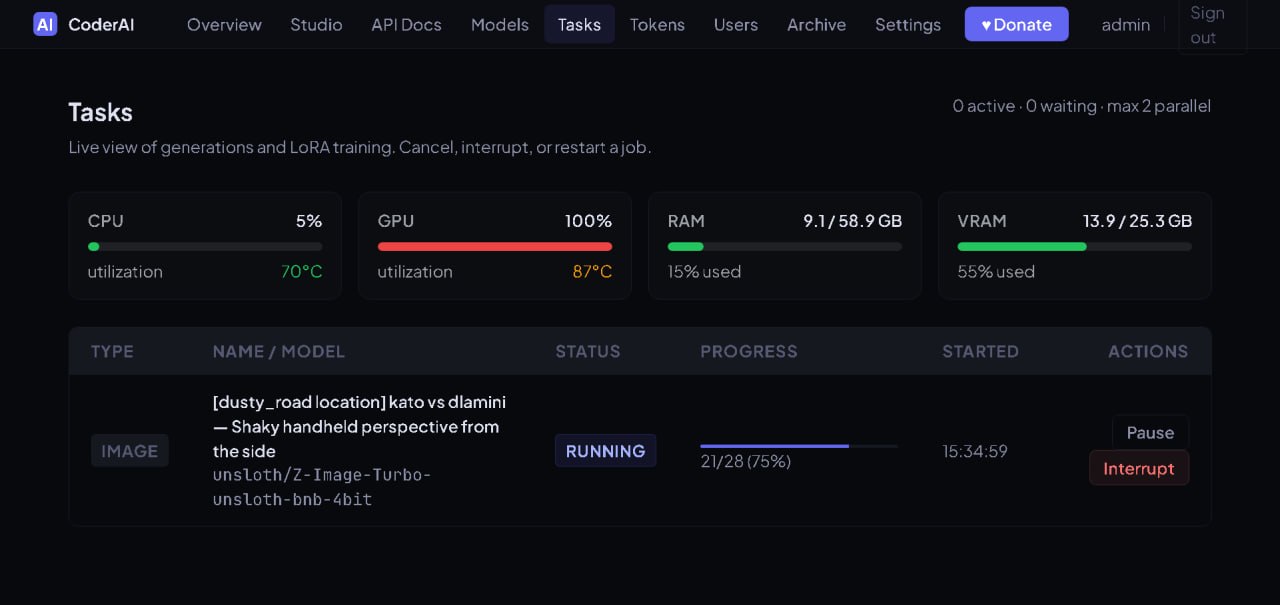
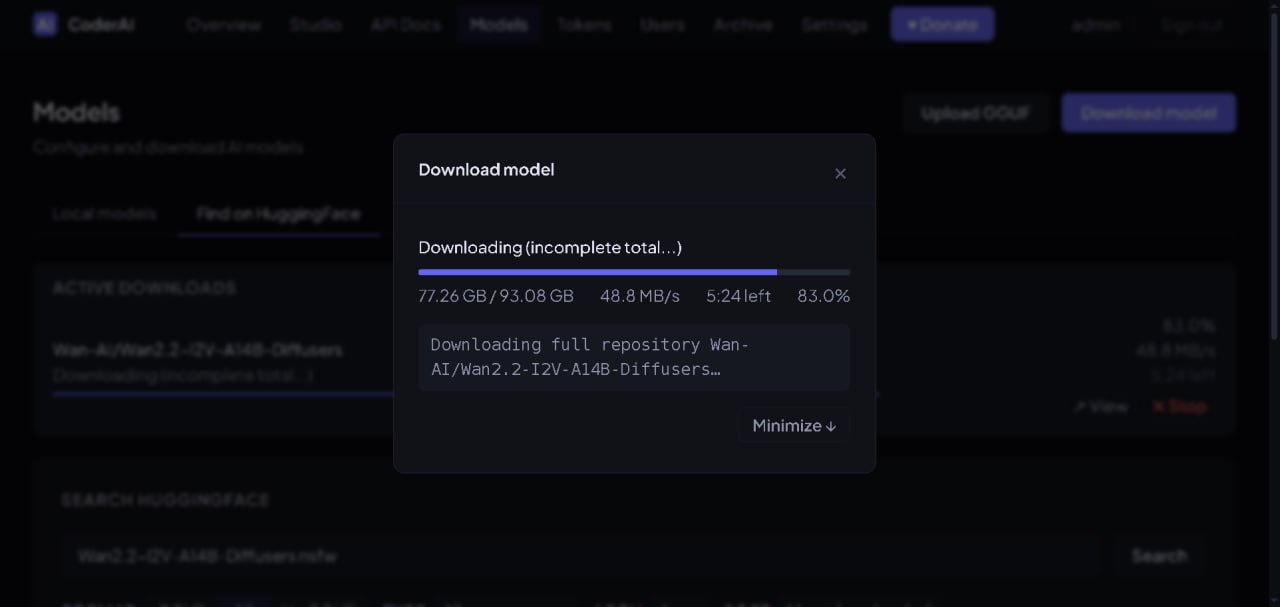
The gallery captures the operational UI that lets a local worker decide how aggressively to fit models into available GPU memory while preserving quality where it matters. Previews are cropped to a consistent size; click any card for a full-size modal preview.
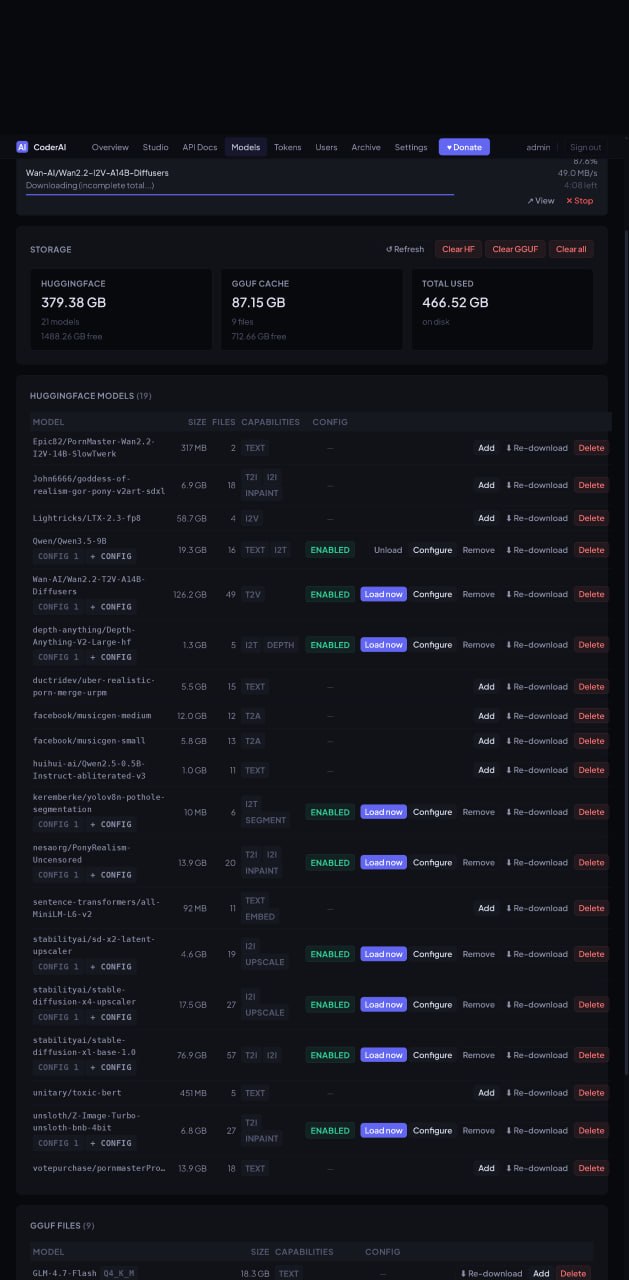
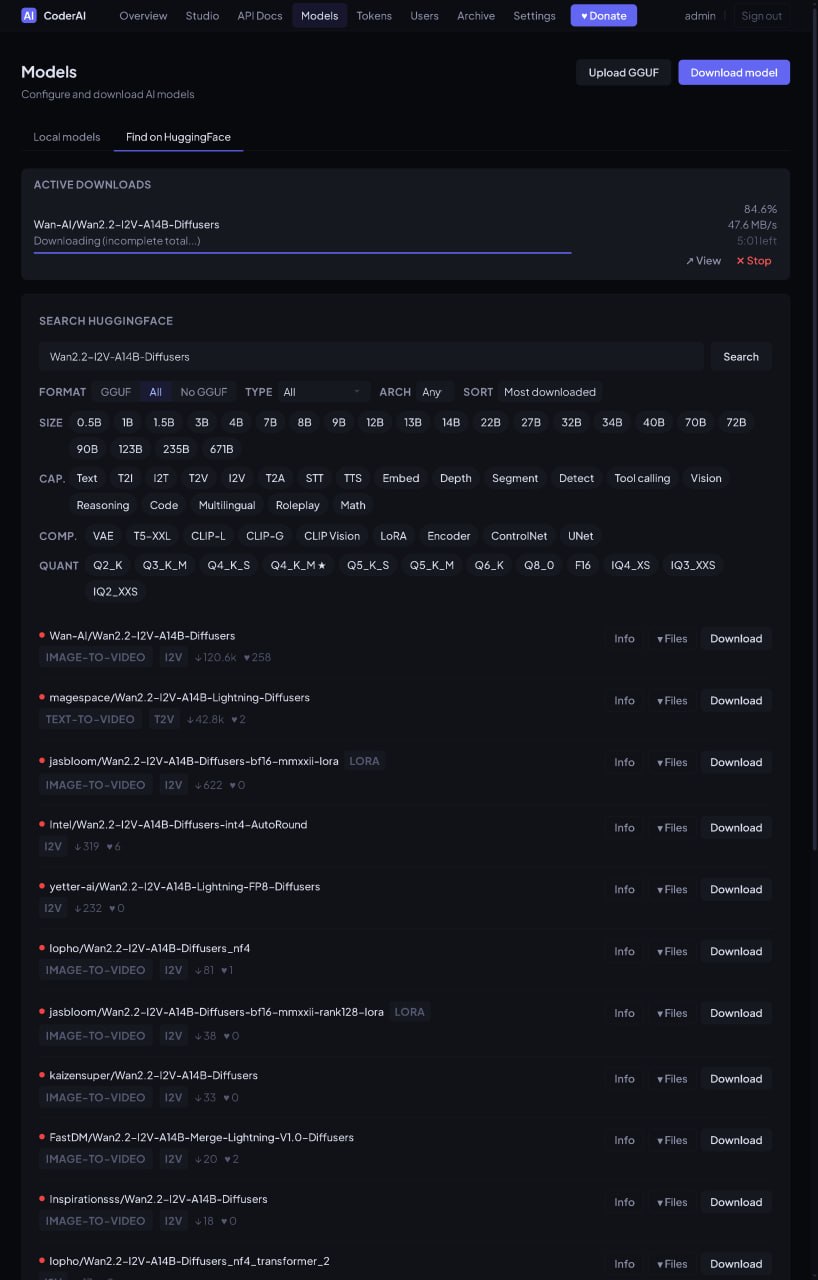
What these controls show.
This is the kind of interface CoderAI exposes for practical local model hosting: not just “download model”, but run-time decisions about memory, backend, and component-level trade-offs.
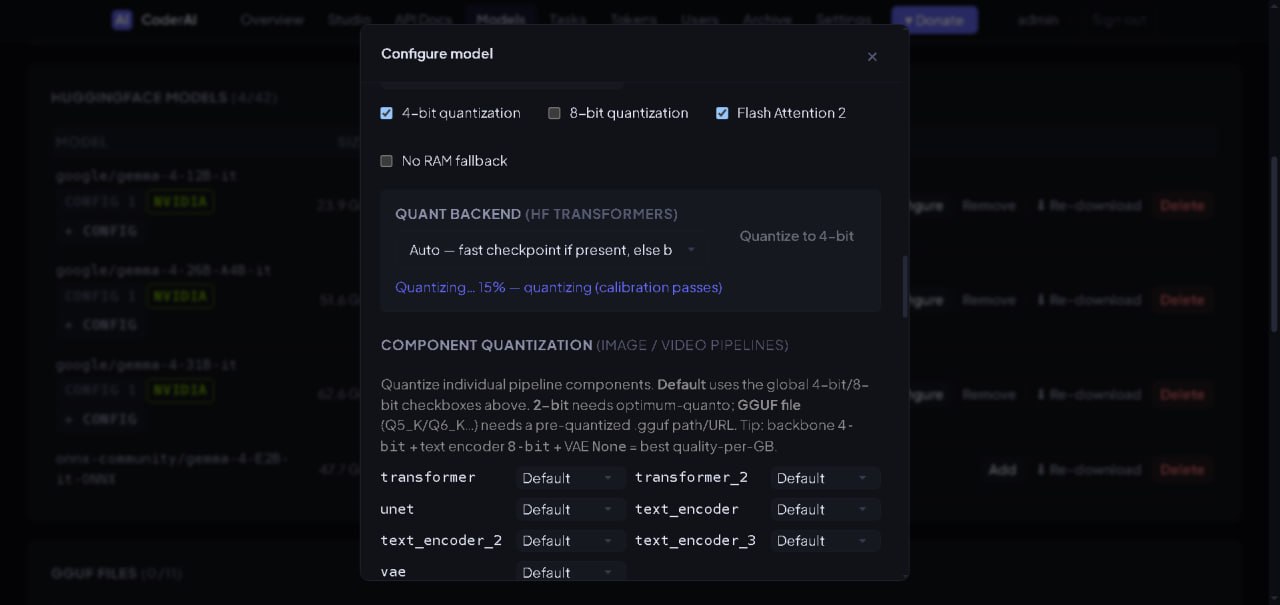
Quantization controls
4-bit and 8-bit toggles help compress heavy models so more workloads fit on smaller GPUs.
Performance toggles
Flash Attention 2 and RAM fallback options expose speed/memory trade-offs directly to the operator.
Pipeline components
Image and video pipelines can tune transformer, text encoder, UNet, and VAE components independently.